Một mô hình ngôn ngữ lớn do Trung Quốc phát triển có tên DeepSeek-R1 đang làm các nhà khoa học phấn khích vì là một đối thủ giá rẻ của các mô hình “suy luận” như o1 của OpenAI.
Những mô hình này tạo ra phản hồi từng bước, tương tự như quá trình suy luận của con người (analogous to human reasoning). Điều này giúp chúng giỏi hơn các mô hình ngôn ngữ trước đây trong việc giải quyết các vấn đề khoa học và có thể hữu ích trong nghiên cứu. Các thử nghiệm ban đầu của R1, được công bố ngày 20 tháng 1, cho thấy hiệu suất của nó trong một số nhiệm vụ về hóa học, toán học và lập trình ngang bằng với o1 — vốn đã gây ấn tượng mạnh khi OpenAI phát hành vào tháng 9.
“Điều này thật đáng kinh ngạc và hoàn toàn bất ngờ,” Elvis Saravia, một nhà nghiên cứu AI và đồng sáng lập công ty tư vấn AI DAIR.AI có trụ sở tại Anh, viết trên X.
R1 nổi bật vì một lý do khác. DeepSeek, công ty khởi nghiệp tại Hàng Châu phát triển mô hình này, đã công bố nó dưới dạng “trọng số mở” (open-weight), cho phép các nhà nghiên cứu có thể tìm tòi và phát triển thêm thuật toán này. Được phát hành theo giấy phép MIT, mô hình có thể được tái sử dụng miễn phí nhưng không được coi là mã nguồn mở hoàn toàn, vì dữ liệu huấn luyện không được công bố.
“Độ mở của DeepSeek thật đáng chú ý,” Mario Krenn, trưởng phòng thí nghiệm Nhà khoa học Nhân tạo tại Viện Max Planck về Khoa học Ánh sáng ở Erlangen, Đức, cho biết. Để so sánh về độ mở, o1 và các mô hình khác do OpenAI ở San Francisco, California phát triển, bao gồm cả phiên bản mới nhất o3, “về cơ bản là những chiếc hộp đen,” ông nói.
DeepSeek không công bố toàn bộ chi phí huấn luyện R1, nhưng mức phí mà công ty này tính cho người dùng chỉ bằng khoảng một phần ba mươi so với chi phí vận hành o1. Công ty cũng tạo ra các phiên bản “tinh lọc” (distilled) mini của R1 để các nhà nghiên cứu với sức mạnh tính toán hạn chế có thể sử dụng mô hình. “Một thí nghiệm tốn hơn 300 bảng Anh với o1 chỉ mất chưa tới 10 đô la Mỹ với R1,” Krenn cho biết. “Sự chênh lệch lớn này chắc chắn sẽ đóng vai trò quan trọng trong việc ứng dụng mô hình trong tương lai.”
Thách thức các mô hình
R1 là một phần trong sự bùng nổ của các mô hình ngôn ngữ lớn (LLM) tại Trung Quốc. Được tách ra từ một quỹ đầu cơ, DeepSeek hầu như ít ai chú ý lúc xuất hiện vào tháng trước khi công bố chatbot V3, vượt qua nhiều đối thủ lớn dù được phát triển với ngân sách eo hẹp (shoestring budget). Các chuyên gia ước tính chi phí thuê phần cứng để huấn luyện mô hình khoảng 6 triệu đô la Mỹ, so với hơn 60 triệu đô la Mỹ của Meta dành cho Llama 3.1 405B, vốn sử dụng lượng tài nguyên tính toán gấp 11 lần.
Một phần lý do DeepSeek gây chú ý là họ đã thành công với R1 bất chấp các hạn chế xuất khẩu của Mỹ, vốn giới hạn khả năng tiếp cận của các công ty Trung Quốc với các con chip AI tiên tiến nhất. “Việc mô hình này xuất phát từ Trung Quốc cho thấy rằng hiệu quả trong sử dụng tài nguyên quan trọng hơn nhiều so với quy mô tính toán đơn thuần,” François Chollet, một nhà nghiên cứu AI tại Seattle, Washington, nhận định.
Tiến bộ của DeepSeek gợi ý rằng “lợi thế mà Mỹ từng được cho là nắm giữ giờ đây đã thu hẹp đáng kể,” Alvin Wang Graylin, một chuyên gia công nghệ tại Bellevue, Washington, thuộc công ty công nghệ HTC có trụ sở tại Đài Loan, viết trên X. “Hai quốc gia cần theo đuổi một cách tiếp cận hợp tác để phát triển AI tiên tiến thay vì tiếp tục cuộc đua vũ trang không có người thắng này.”
Dòng suy nghĩ
Các LLM được huấn luyện trên hàng tỷ mẫu văn bản, chia nhỏ chúng thành các phần của từ gọi là “token” và học các mẫu trong dữ liệu. Những liên kết này cho phép mô hình dự đoán các token tiếp theo trong một câu. Tuy nhiên, LLM có xu hướng “bịa” thông tin, hiện tượng được gọi là “ảo giác,” và thường gặp khó khăn trong việc suy luận để giải quyết các vấn đề (reason through problems).
Giống như o1, R1 sử dụng phương pháp “chuỗi suy nghĩ” (chain of thought) để cải thiện khả năng giải quyết các nhiệm vụ phức tạp hơn, bao gồm đôi khi lần ngược lại và đánh giá lại cách tiếp cận của mình. DeepSeek đã tạo R1 bằng cách “tinh chỉnh” chatbot V3 thông qua học tăng cường (reinforcement learning), trong đó mô hình được thưởng khi đạt được câu trả lời đúng và khi giải quyết vấn đề theo cách nêu rõ quá trình “suy nghĩ” của nó.
Việc hạn chế sức mạnh tính toán đã thúc đẩy công ty “đổi mới thuật toán,” Wenda Li, một nhà nghiên cứu AI tại Đại học Edinburgh, Anh, cho biết. Trong quá trình học tăng cường, nhóm nghiên cứu đã ước lượng tiến độ của mô hình ở từng giai đoạn, thay vì đánh giá nó từ một hệ thống riêng biệt. Điều này giúp giảm chi phí huấn luyện và vận hành, Mateja Jamnik, nhà khoa học máy tính tại Đại học Cambridge, Anh, chia sẻ. Các nhà nghiên cứu cũng sử dụng kiến trúc “hỗn hợp chuyên gia” (mixture-of-experts), cho phép mô hình chỉ kích hoạt các phần liên quan đến từng nhiệm vụ.
Trong các bài kiểm tra chuẩn, được báo cáo trong một bài báo kỹ thuật kèm theo mô hình, DeepSeek-R1 đạt 97,3% trong bộ bài toán MATH-500 do OpenAI tạo ra và vượt qua 96,3% người tham gia trong cuộc thi Codeforces. Đây là các kết quả ngang ngửa với khả năng của o1; o3 không được đưa vào so sánh.
Thật khó để biết liệu các bài kiểm tra chuẩn có thực sự phản ánh khả năng suy luận hay khái quát hóa của mô hình, hay chỉ đơn thuần là vượt qua các bài kiểm tra đó. Nhưng vì R1 là một mô hình mở, chuỗi suy nghĩ của nó có thể được các nhà nghiên cứu tiếp cận, Marco Dos Santos, nhà khoa học máy tính tại Đại học Cambridge, nhận định. “Điều này cho phép diễn giải tốt hơn các quy trình suy luận của mô hình,” ông nói.
Hiện tại, các nhà khoa học đang thử nghiệm khả năng của R1. Krenn đã thách thức cả hai mô hình đối thủ trong việc phân loại 3.000 ý tưởng nghiên cứu dựa trên mức độ thú vị và so sánh kết quả với xếp hạng của con người. Theo tiêu chí này, R1 kém hơn o1 một chút. Nhưng R1 lại vượt o1 trong một số phép tính trong quang học lượng tử, Krenn cho biết. “Đây là điều khá ấn tượng.”
Công ty DeepSeek của Trung Quốc cho ra mắt mô hình ngôn ngữ lớn năm 2024. Ảnh: Koshiro K/Alamy
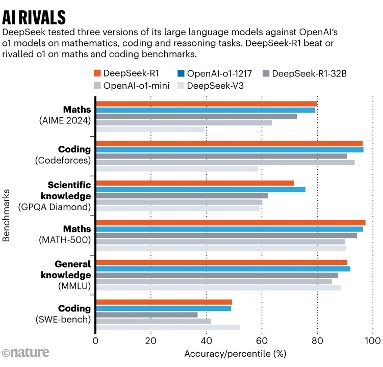
DeepSeek thử nghiệm ba mô hình ngôn ngữ lớn để so sánh với mô hình o1 của OpenAI về toán học, lập trình và khả năng lập luận. DeepSeek-R1 vượt qua hoặc ngang bằng với o1 theo các bài kiểm tra chuẩn về toán học và lập trình. Ảnh: DeepSeek